在来自独立源的数据的随机集合中,通常观察到数据的分布是正常的。 这意味着,在绘制水平轴上的变量值和垂直轴上的值的计数的图形时,我们得到钟形曲线。 曲线的中心表示数据集的平均值。 在图中,50%的值位于平均值的左侧,另外50%位于图表的右侧。 这在统计学中被称为正态分布。
R语言有四个内置函数来产生正态分布。 它们描述如下。
dnorm(x, mean, sd) pnorm(x, mean, sd) qnorm(p, mean, sd) rnorm(n, mean, sd)
以下是在上述功能中使用的参数的描述 -
x是数字的向量。
p是概率的向量。
n是观察的数量(样本大小)。
mean是样本数据的平均值。 它的默认值为零。
sd是标准偏差。 它的默认值为1。
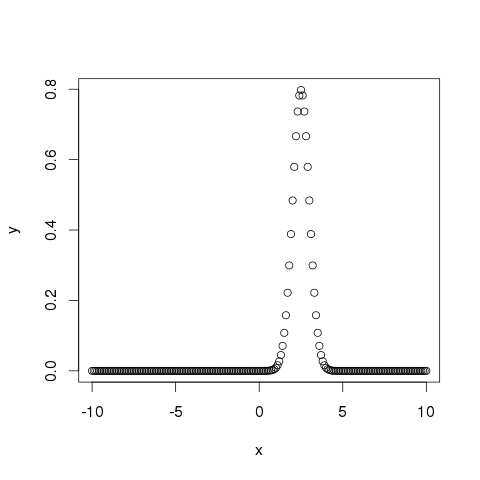
dnorm()
该函数给出给定平均值和标准偏差在每个点的概率分布的高度。
# Create a sequence of numbers between -10 and 10 incrementing by 0.1. x <- seq(-10, 10, by = .1) # Choose the mean as 2.5 and standard deviation as 0.5. y <- dnorm(x, mean = 2.5, sd = 0.5) # Give the chart file a name. png(file = "dnorm.png") plot(x,y) # Save the file. dev.off()
当我们执行上面的代码,它产生以下结果 -
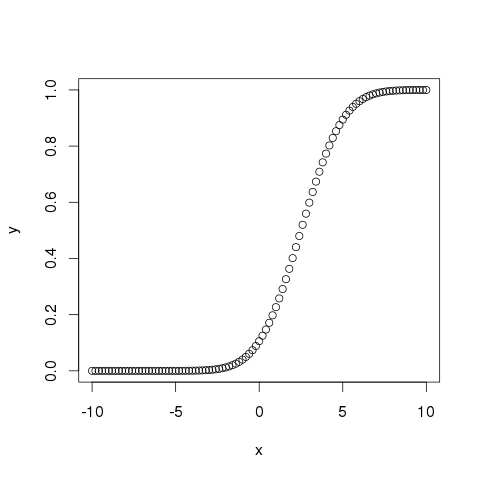
pnorm()
该函数给出正态分布随机数的概率小于给定数的值。 它也被称为“累积分布函数”。
# Create a sequence of numbers between -10 and 10 incrementing by 0.2. x <- seq(-10,10,by = .2) # Choose the mean as 2.5 and standard deviation as 2. y <- pnorm(x, mean = 2.5, sd = 2) # Give the chart file a name. png(file = "pnorm.png") # Plot the graph. plot(x,y) # Save the file. dev.off()
当我们执行上面的代码,它产生以下结果 -
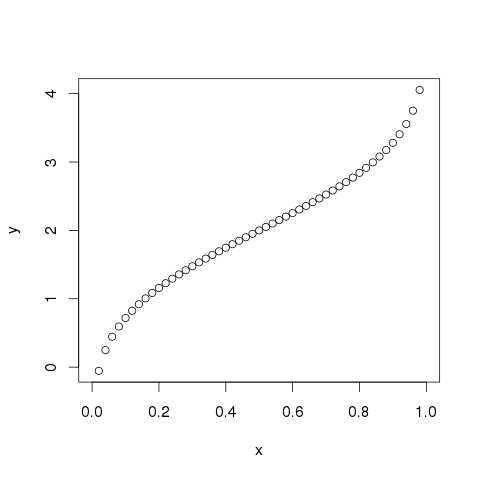
qnorm()
该函数采用概率值,并给出累积值与概率值匹配的数字。
# Create a sequence of probability values incrementing by 0.02. x <- seq(0, 1, by = 0.02) # Choose the mean as 2 and standard deviation as 3. y <- qnorm(x, mean = 2, sd = 1) # Give the chart file a name. png(file = "qnorm.png") # Plot the graph. plot(x,y) # Save the file. dev.off()
当我们执行上面的代码,它产生以下结果 -
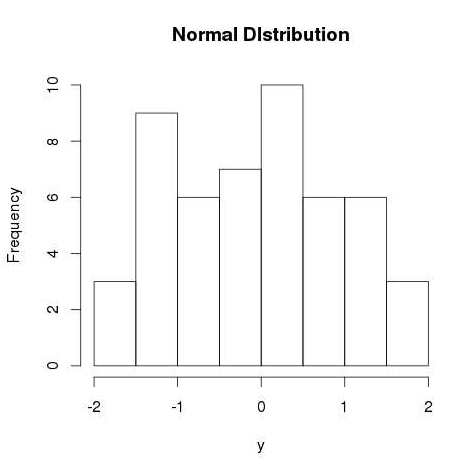
RNORM()
此函数用于生成分布正常的随机数。 它将样本大小作为输入,并生成许多随机数。 我们绘制一个直方图来显示生成的数字的分布。
# Create a sample of 50 numbers which are normally distributed. y <- rnorm(50) # Give the chart file a name. png(file = "rnorm.png") # Plot the histogram for this sample. hist(y, main = "Normal DIstribution") # Save the file. dev.off()
当我们执行上面的代码,它产生以下结果 -